샷건치며 배우는 자료구조 with C++, 6화
큐에 대해 알아봅시다.
읽어주세요
자료구조를 배우기 위해 위대한 항로(?)를 넘어 여기까지 오신 분들 환영합니다. 본 게시글은 자료구조를 공부하면서 복습 겸 정리하기 위해 작성하였습니다. 개인적으로 강좌 형식 및 장난을 섞어가며 작성하는 걸 좋아하기 때문에 진지한 게시글을 원하신다면 뒤로 가기를 눌러주세요.
C++ 언어를 기반으로 하고 있습니다. 다른 프로그래밍 언어를 사용 중이신 경우 개념(이론)을 배우는 데 큰 문제는 없지만, 실제 코드로 구현할 땐 생각보다 차이가 있을 수 있습니다.
업데이트
- C 언어 구현 내용 제거
- 게시글의 내용이 너무 복잡해져 제거하였습니다.
게시글 개선을 위해 임시 숨김 처리
큐
솔큐, 다인큐라는 용어를 아시나요? 주로 게임에서 사용하는 용어인데요, 솔큐는 솔로 플레이를 의미하고 다인큐는 여러 명과 함께 플레이하는 것을 의미합니다. 이 두 용어는 공통적으로 '큐'라는 단어를 수식하고 있고, 오늘 배울 자료구조 큐와 관련되어 있습니다.
큐Queue는 '대기줄'이라는 뜻을 지니고 있습니다. 햄버거를 주문하기 위해 키오스크 앞에 줄을 서거나, 놀이기구를 타기 위해 줄을 서는 등 줄을 서서 내 차례가 오기만을 기다리죠.
자료구조에서 큐는 스택과 함께 대표적인 선형 자료구조로, 먼저 들어간 데이터가 먼저 나오는 선입선출FIFO, First In First Out 방식으로 동작합니다. 이 자료구조는 대표적으로 순서를 보장하고 싶을 때 사용합니다.
스택은 끝에서 데이터를 다뤘다면 큐는 앞에서 데이터를 다루며, 스택과 마찬가지로 배열 또는 연결 리스트를 기반으로 구현할 수 있습니다. 우리는 아직 연결 리스트를 배우지 않았기 때문에 이번에도 배열 기반으로 알아보도록 합시다.
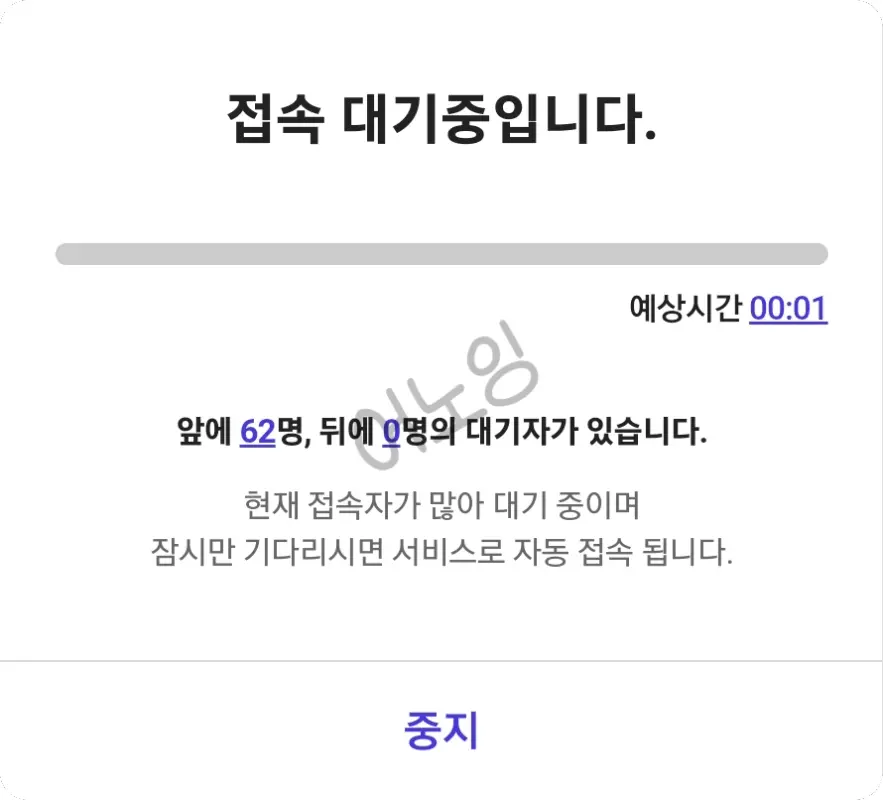
자료구조의 큐는 조금 더 있어보이게(?) '대기열'이라고 부르기도 합니다.
위 사진 예시는 T멤버십 제로데이의 혜택 중 하나인 쿠폰을 얻기 위해 정각에 맞추어 접속했을 때 나타나는 화면입니다. 제 앞에 62명이 존재하는데, 저보다 먼저 데이터를 송신했기 때문에 서로 자기 차례가 오기만을 기다리고 있습니다. 자기 차례가 되면 쿠폰을 발급 받을 수 있는 페이지에 접속할 수 있죠.
만약 큐를 사용하지 않으면 모든 사용자의 데이터가 서로 접속하겠다고 전달하기 때문에 서버에 많은 부하를 주게됩니다. 운이 나쁘다면 서버 다운으로 이어지죠. 위 티멤버십의 큐는 조금 더 안전한 사용을 위해 대기 시간을 부여하여 일정 시간이 지나면 접속할 수 있도록 하고 있습니다.
특징
-
선입선출
자료구조 큐는 먼저 추가된 데이터가 먼저 제거될 수 있는 선입선출 구조를 따릅니다. 후입후출이라고 부르기도 합니다.
-
 앞과 뒤
앞과 뒤
큐는
front와rear라 부르는 인덱스 변수를 사용합니다.front는 앞을 가리키고,rear는 뒤를 가리킵니다.front는DEQUEUE연산을 수행할 때 주로 사용되고,rear는ENQUEUE연산을 수행할 때 사용됩니다.back이 아닌 rear를 사용하는 이유?
back과 rear는 둘 다 '뒤쪽'이라는 의미를 갖고 있지만, 서로 사용하는 상황과 뉘앙스가 다릅니다.
back은 일반적인 뒤쪽으로, 몸의 등이나 물체의 뒷면을 의미합니다. rear는 정확한 끝 부분을 의미하는데, 차량의 뒷부분 등 정확히 끝 부분을 의미할 때 사용합니다. 그래서 자료구조 큐에서 제일 끝을 의미하기 위해 rear라는 단어를 사용합니다.
-
 제한
제한
큐는 앞에만 접근할 수 있습니다. 그래서 중간에 있는 데이터를 확인하려면 일일이 제거하면서 찾아야 합니다.
장단점
-
장점
-
공정한 처리
데이터의 처리 순서를 보장하기 때문에 공정한 기회를 제공합니다.
-
간단한 구현
배열 또는 연결 리스트를 기반으로 하기 때문에 비교적 구현이 간단합니다.
-
-
단점
-
중간 데이터 접근 불가
스택처럼 중간에 있는 데이터에 접근할 수 없습니다. 큐는 앞에만 접근할 수 있습니다.
-
아쉬운 메모리 효율
배열을 기반으로 하는 큐는 크기가 고정되기 때문에 메모리가 부족하거나 낭비되는 경우가 발생합니다. 이러한 단점은 아래에서 배울 원형 큐를 통해 어느정도 해소 가능합니다.
-
성능
원형 큐가 아닌 선형 큐에서 데이터 제거 연산인
DEQUEUE를 수행할 경우 시프트 연산을 필요로 합니다. 즉, 앞에 데이터가 제거되면 뒤에 있는 모든 데이터를 앞으로 이동시켜야 합니다.
-
작동 원리

배열을 기반으로 하는 선형 큐의 작동 원리는 생각보다 간단합니다.
front는 큐의 앞을 의미하는 인덱스 변수입니다. 이 변수의 값이 증가하면 다음 데이터를 가리킵니다. rear는 큐의 뒤를 의미하는 인덱스 변수로, 큐에서 데이터가 추가될 위치를 가리킵니다. 시프트 연산을 사용할 경우 front와 rear는 각각 0과 -1의 값을 초깃값으로 합니다. rear의 초깃값을 -1로 설정할 경우 큐가 비어 있다는 상태를 더 명확히 표현할 수 있습니다.
ENQUEUE 연산은 데이터를 큐의 맨 뒤(rear)에 추가합니다. 이 과정에서 rear의 값이 1씩 증가합니다.
DEQUEUE 연산은 큐의 앞(front)에서 데이터를 제거합니다. 기본적으로 front의 값을 1씩 증가시키는데요, 시프트 연산을 사용한다면 증가 연산을 수행하지 않습니다. 왜냐하면 시프트 연산을 사용하면 데이터가 항상 앞으로 이동하기 때문에 굳이 연산을 수행할 필요가 없습니다. 그래서 항상 0으로 초기화하여 사용합니다.
시프트 연산은 필수가 아닙니다. 그럼에도 제가 필수인 것처럼 언급하는 이유는 DEQUEUE 연산으로 인해 생기는 앞쪽 빈 공간을 재활용하기 위해서입니다. 이 연산을 수행하지 않으면 front가 배열의 끝에 도달했을 때 더 이상 사용할 수 없는 상황을 방지하기 위해서입니다. front와 rear의 값이 서로 같아지면 앞의 빈 공간을 더 이상 활용할 수 없어집니다. 시프트 연산은 \(O(n)\) 시간 복잡도를 가지지만 큐를 지속적으로 사용할 수 있도록합니다.
성능 문제가 발생하기 때문에 이를 해결하기 위한 방법으로 원형 큐를 사용하는데, 조금 있다가 알아봅시다.
기본 구조
| queue_frame.cpp | |
|---|---|
선형 큐의 기본 구조는 위 코드 예시와 같습니다.
선형 큐는 배열을 기반으로 하기 때문에 고정된 크기를 갖습니다. 그래서 고정된 크기를 의미하는 MAX_SIZE 상수 매크로를 선언합니다.
front는 큐의 앞을 가리키는 인덱스 변수이며, 데이터를 제거할 때 사용됩니다. rear는 큐의 끝을 가리키는 인덱스 변수이며, 데이터를 추가할 때 사용됩니다. 이때 rear의 값이 -1이면 큐가 비어 있음을 나타냅니다.
주요 연산
큐의 주요 연산은 ENQUEUE와 DEQUEUE입니다. 나머지 연산은 큐의 보조적인 역할을 수행합니다.
스택과 마찬가지로 단순함을 추구하기 때문에 별도의 복잡한 연산은 구현할 필요가 없습니다.
ENQUEUE
ENQUEUE 연산은(1) 큐가 가득 차 있지 않을 때 rear 변수가 가리키는 위치에 데이터를 추가합니다.
ENQUEUE에서 'EN'은 'Enter'를 의미하며, 큐에 데이터를 추가(입력)한다는 의미를 가진 접두사입니다.
큐가 가득 차 있지 않은 지 확인하고, rear가 가리키는 위치에 데이터를 추가한 후 rear의 값만 단순히 증가시키기 때문에 시간 복잡도는 \(O(1)\)입니다.
데이터를 추가하기 전에 큐의 공간을 확인하는 이유는 안전한 연산을 수행하기 위해서입니다. 즉 큐 오버플로우Queue Overflow를 방지하기 위해서입니다. 주로 고정된 크기를 갖는 배열 기반의 큐에서 발생합니다. 기본적으로 정해진 크기를 넘어 데이터를 추가할 수 없습니다. 이를 가능하게 하면 엉뚱한 곳(또는 사용 중인 영역)에 데이터를 기록하기 때문에 오류 및 충돌을 불러 일으킬 수 있습니다. 연결 리스트 기반의 경우 시스템의 메모리가 부족해지면 발생할 수 있습니다.
-
인덱스 증가
조건문으로 큐에 빈 공간이 있는 지 확인합니다. 그리고
rear의 초깃값은-1이기 때문에 먼저 인덱스의 값을 증가시킵니다.인덱스의 값을 먼저 증가시키는 이유는 큐의 데이터 추가가 맨 끝에서 이루어지기 때문입니다.
-
데이터 추가
데이터 추가는 간단합니다.
rear가 가리키는 위치에 데이터를 기록하면 됩니다.
| queue.cpp | |
|---|---|
C++ STL에 std::queue 컨테이너가 존재합니다. 자료구조 큐를 구현한 템플릿 클래스입니다. 이 컨테이너는 std::deque 컨테이너를 기반으로 하기 때문에 고정된 크기를 갖지 않고 동적으로 조절됩니다.
이 컨테이너에서 데이터를 추가하는 연산은 push() 메서드가 수행합니다.
DEQUEUE
DEQUEUE 연산은(1) 큐가 빈 상태가 아닐 때 front 변수가 가리키는 위치에 있는 데이터를 제거합니다.
DEQUEUE에서 'DE'는 'Delete'를 의미하며, 큐에 데이터를 제거한다는 의미를 가진 접두사입니다.
시프트 연산이 없다면 front 변수의 값만 증가하면 끝이라 시간 복잡도는 \(O(1)\)입니다. 하지만 시프트 연산이 포함된다면 데이터 제거 후 남은 요소들을 앞으로 이동시켜야 하기 때문에 \(O(n)\) 시간 복잡도로 수행됩니다. 그리고 시프트 연산이 포함되면 front 변수의 값은 증가시키지 않고 0 그대로 둡니다. 왜냐하면 앞만 가리키면 되니까요.
데이터를 제거하기 전에 큐의 공간을 확인하는 이유는 안전한 연산을 위해서입니다. 즉 큐 언더플로우Queue Underflow를 방지하기 위함입니다. 주로 고정된 크기를 갖는 배열 기반의 큐에서 발생합니다. 데이터가 없는 상태에서 제거하려 하면 잘못된 메모리 접근이나 의미없는 값을 반환하게 되죠. 연결 리스트 기반의 큐에서도 빈 상태인지 확인을 해야합니다.
-
시프트 연산
시프트 연산을 포함하지 않는다면 단순히
front변수의 값을 증가시키면 됩니다.하지만 시프트 연산을 포함한다면
front변수를 다루지 않고 데이터를 이동시키는 연산을 수행합니다. 데이터는0부터rear + 1까지를 이동시키면 됩니다. 왜냐하면 요소가 하나만 추가되면rear의 값은0인데 반복문의 조건식에서1을 더하지 않으면 반복문이 수행되지 않기 때문입니다. -
인덱스 감소
시프트 연산을 포함한다면
rear변수의 값을1씩 감소시키면 됩니다.시프트 연산을 포함하지 않는다면
rear변수의 값을 감소시키지 말고front변수의 값을 증가시킨 후,front가rear보다 커지는 지 조건문으로 확인 후 초깃값으로 되돌리는 코드를 작성해야 합니다. 왜냐하면 모든 요소가 제거되면front가rear와 같아져 더 이상 큐를 사용할 수 없게 됩니다. 큐를 처음부터 다시 재활용하기 위해 초깃값으로 되돌리는 겁니다.
| queue_dequeue2.cpp | |
|---|---|
pop() 메서드로 데이터를 앞에서 부터 제거할 수 있습니다. 이 메서드를 호출하기 전에 큐가 비어 있는 지 확인할 수 있는 empty() 메서드를 호출하여 사전 검사를 수행해야 합니다.
FRONT
FRONT 연산은 큐의 앞을 가리키는 위치에 있는 요소의 값을 반환합니다. 기본적으로 DEQUEUE 연산은 값을 제거만 하고 반환하지 않습니다. 물론 구현 방식에 따라 반환하도록 할 수 있습니다.
이 연산은 큐가 비어 있지 않다면 front 위치에 있는 값을 반환합니다. 해당 위치에 접근하여 값을 반환하기 때문에 시간 복잡도는 \(O(1)\)입니다.
큐는 선입선출 방식으로 처리되기 때문에 앞에만 접근할 수 있습니다. 뒤의 데이터를 제거하거나 확인하려면 DEQUEUE 연산으로 일일이 제거 및 확인해야 합니다.
-
비어있는 지 확인
rear의 값이-1이면 비어 있다는 걸 의미하기 때문에 반환할 수 있는 값이 없습니다.-1을 반환하도록 합니다. -
반환
front위치에 있는 값을 반환합니다.
| queue_front2.cpp | |
|---|---|
front() 메서드로 앞의 데이터를 확인할 수 있습니다.
IS EMPTY
IS EMPTY 연산은 큐가 비어 있는 지 확인합니다.
rear == -1 또는 rear < front를 조건식으로 검사하기 때문에 시간 복잡도는 \(O(1)\)입니다.
rear의 값이 -1이면 비어있음을 나타냅니다.
| queue_isempty2.cpp | |
|---|---|
empty() 메서드로 큐가 비었는 지 안 비었는 지 Boolean 형식으로 확인할 수 있습니다.
IS FULL
IS FULL 연산은 IS EMPTY 연산과는 다르게 큐가 꽉 차 있는 지 확인합니다. 이 연산은 배열 기반에서만 사용되고, rear가 MAX_SIZE - 1인지 확인하기 때문에 시간 복잡도는 \(O(1)\)입니다.
rear의 값이 -1이면 비어있음을 나타냅니다.
std::queue 컨테이너에는 isFull()과 같은 메서드가 없습니다. 왜냐하면 내부적으로 std::deque 컨테이너를 사용하여 동적으로 크기가 변하기 때문입니다.
SIZE
SIZE 연산은 현재 큐에 저장된 데이터의 수를 반환합니다. 단순 연산만 수행하기 때문에 시간 복잡도는 \(O(1)\)입니다.
rear에서 front를 뺀 값에 1을 더하면 현재 큐에 저장된 데이터의 수를 구할 수 있습니다.
front를 빼는 이유는 시프트 연산을 사용하지 않을 때를 위해서입니다. 시프트 연산을 사용한다고 해도 값이 0 고정이라 연산에 지장이 없습니다.
CLEAR
CLEAR 연산은 큐를 비우고 초기 상태로 되돌립니다.
front와 rear의 값만 초깃값으로 되돌리기 때문에 시간 복잡도는 \(O(1)\)입니다.
std::queue 컨테이너는 별도의 clear() 메서드가 없습니다. 큐를 비우려면 empty() 메서드로 빌 때까지 pop() 메서드를 이용해 제거해야 하며, 시간 복잡도는 \(O(n)\)입니다.
원형 큐
지금까지 일반적인 큐... 즉 선형 큐에 대해 알아보았는데요, 어떠신가요?
처음 큐를 설명할 때 DEQUEUE 연산을 수행할 때마다 앞 쪽에 빈 공간이 생기기 때문에 성능 저하를 감수하더라도 조금 더 효율적으로 사용하기 위해 시프트 연산을 수행한다고 했습니다. 근데 생각해보면 좀 비효율적이지 않나요? 데이터를 제거할 때 마다 \(O(n)\)의 시간 복잡도가 발생하니까요. 데이터가 ㅈㄴ 많았다면 꽤 끔찍하죠?
그래서 등장한 게 원형 큐입니다. 원형 큐는 인덱스만 조작하여 \(O(1)\)의 시간 복잡도로 연산해낼 수 있습니다.
원형 큐Circular Queue는 선형 큐처럼 고정된 크기의 배열을 사용하면서, 논리적으로 처음과 끝이 서로 연결된 구조를 갖는 큐입니다. 쉽게 말하자면 마지막 인덱스의 다음이 처음 인덱스로 연결된다는(되돌아간다는) 소립니다.
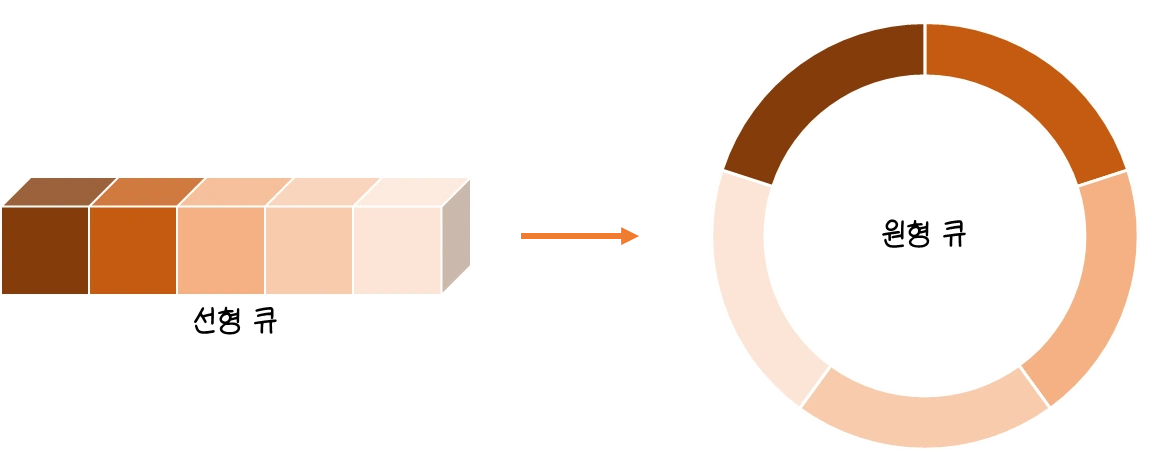
복잡하죠? 다시 정리하자면 원형 큐는 선형 큐의 단점인 성능 저하를 해결하기 위한 큐의 자료구조 중 하나입니다. 배열의 끝에 도달했을 때 다시 처음으로 돌아가 공간을 재활용합니다.
배열을 논리적으로 원형으로 간주하여 front 또는 rear가 배열의 끝(MAX_SIZE - 1)에 도달하면 다음 위치를 0으로 되돌립니다.
특징
-
순환
고정된 크기의 배열을 활용하지만 논리적으로 처음과 끝이 연결된 구조를 가져 순환할 수 있습니다.
-
빠른 속도
선형 큐는 시프트 연산을 사용하지 않아 데이터의 제거를 \(O(1)\) 시간 복잡도로 연산을 수행해낼 수 있습니다.
장단점
-
장점
-
공정한 처리
데이터의 처리 순서를 보장하기 때문에 공정한 기회를 제공합니다.
-
간단한 구현
배열 또는 연결 리스트를 기반으로 하기 때문에 비교적 구현이 간단합니다.
-
성능
시프트 연산을 사용하지 않아
DEQUEUE연산이 \(O(1)\)으로 수행됩니다.
-
-
단점
-
중간 데이터 접근 불가
스택과 마찬가지로 중간에 있는 데이터에 접근할 수 없습니다. 큐는 앞 만 접근할 수 있습니다.
-
아쉬운 메모리 효율
선형 큐랑 같은 단점을 공유합니다. 고정된 크기의 배열을 사용하기 때문에 새 데이터를 추가하기 힘듭니다. 기존의 데이터를 제거해야합니다.
-
작동 원리

사진이 좀 복잡해보이죠? 생각보다 작동 원리는 간단합니다.
원형 큐는 초기에 큐가 비어 있음을 나타내기 위해 front와 rear의 값을 -1로 초기화합니다.
선형 큐와 달리 시프트 연산을 수행하지 않기 때문에 front와 rear가 배열의 끝(MAX_SIZE - 1)에 도달하면 모듈러 연산나머지 연산을 통해 처음으로 되돌아갑니다. 원형 큐는 front와 rear가 순환하면서 큐를 관리합니다.
-
빈 원형 큐에서 데이터 추가
초기 빈 원형 큐에서
ENQUEUE연산을 수행하면front의 값이0으로 설정됩니다. 즉, 첫 데이터 추가 시에만0으로 설정하고 이후에는ENQUEUE에서 건드리지 않습니다.front는 기본적으로 데이터를 제거하는DEQUEUE에서 사용되기 때문입니다.rear의 값은rear = (rear + 1) % MAX_SIZE연산을 통해 인덱스의 값을 관리합니다. 여기서 모듈러 연산을 수행하는 이유는rear의 값이 배열의 크기(MAX_SIZE)를 넘어서면 올바른 인덱스가 아니기 때문에 그렇습니다. 즉 처음으로 되돌아 가기 위해 모듈려 연산을 수행합니다.MAX_SIZE가4일 때rear의 값도4가 되면 배열의 크기를 넘어섭니다. 그래서MAX_SIZE로 나눈 후 나머지 값인0으로 되돌려 처음으로 돌아가게 만드는 원리입니다. 이러면 문제없이 순환을 수행해낼 수 있습니다. -
꽉 찬 원형 큐
Enqueue(1),Enqueue(2),Enqueue(3),Enqueue(4)를 수행하면 큐가 꽉 찹니다. 이 상태에서 데이터를 더 추가하려면 기존의 데이터를 제거해야 합니다. -
DEQUEUEfront의 값은ENQUEUE연산과 마찬가지로front = (front + 1) % MAX_SIZE연산을 통해 인덱스의 값을 관리합니다. 선형 큐와 마찬가지로 큐가 빈 상태라면 제거할 수 없기 때문에front와rear변수를 초기 값으로 되돌리는 조건이 필요합니다.front가rear와 같아지면 마지막 요소라는 것을 의미하기 때문에 이때 초기 값으로 되돌리면 됩니다.
기본 구조
| circular_queue_frame.cpp | |
|---|---|
기본 구조는 선형 큐의 기본구조와 같습니다.
원형 큐도 배열을 기반으로 하기 때문에 고정된 크기를 갖습니다. 그래서 고정된 크기를 의미하는 MAX_SIZE 상수 매크로를 선언합니다.
front는 큐의 앞을 가리키는 인덱스 변수이며, 데이터를 제거할 때 사용됩니다. rear는 큐의 끝을 가리키는 인덱스 변수이며, 데이터를 추가할 때 사용됩니다.
주요 연산
원형 큐의 주요 연산은 ENQUEUE와 DEQUEUE로, 선형 큐와 같습니다.
ENQUEUE
ENQUEUE 연산은 큐가 가득 차 있지 않을 때 rear 변수가 가리키는 위치에 데이터를 추가합니다. 선형 큐와 작동 방식이 같습니다.
단순 할당, 비교 연산만 있기 때문에 시간 복잡도는 \(O(1)\)입니다.
C++ STL에서 원형 큐를 기반으로 하는 자료구조 컨테이너가 없습니다. 그래서 직접 구현해야 합니다.
-
가득 차 있는지 확인
원형 큐는 순환 구조를 사용하기 때문에 선형 큐의
read == (MAX_SIZE - 1)조건으로 가득 찼는지 확인할 수 없습니다. 이 조건은 단순히rear가 배열의 마지막 인덱스에 도달했음을 의미할 뿐, 큐가 실제로 가득 찼다는 걸 보장하지 못합니다. 예를 들어,rear = MAX_SIZE - 1라도front가 앞쪽에 위치해 있다면 빈 공간이 남아 있을 수 있기 때문입니다.그래서 원형 큐에서는
((rear + 1) % MAX_SIZE) == front조건으로 가득 차있는지 확인할 수 있습니다.rear가 한 칸 더 이동했을 때front와 같은 위치에 있다면 더 이상 빈 공간이 없음을 나타냅니다. 조금 더 쉽게 설명드리자면...rear는 마지막 요소의 위치를 가리키고,front는 첫 번째 요소의 위치를 가리킵니다.((rear + 1) % MAX_SIZE)로 다음 요소가 추가될 위치를 계산해서 이 위치가front와 같다면front가 가리키고 있는 위치에 데이터를 덮어쓰는 것이기 때문에 가득 차 있다고 판단하는 것입니다. -
첫 요소 추가 확인
front와rear의 값을-1로 초기화했습니다.rear는ENQUEUE연산을 수행할 때 마다 인덱스 값이 관리되기 때문에 상관없지만,front는DEQUEUE연산에서 관리됩니다. 그런데-1인 상태로DEQUEUE연산을 수행하면 잘못된 동작이 발생할 수 있습니다. 데이터가 없다고 판단되어 제거를 수행하지 않겠죠? 그래서ENQUEUE연산에서 첫 요소를 추가할 때에만front의 값을0으로 설정해 첫 요소를 가리키게 하는 겁니다. -
인덱스 증가
rear에1을 더해 뒤를 가리키도록 합니다.1을 더할 때 배열의 크기(MAX_SIZE)를 넘어설 수 있기 때문에 모듈러 연산을 통해 인덱스 범위를 적절히 사용하도록 합니다.
DEQUEUE
DEQUEUE 연산은 큐가 빈 상태가 아닐 때 front 변수가 가리키는 위치에 있는 데이터를 제거합니다. 선형 큐의 작동 방식과 같습니다.
단순 할당, 비교 연산만 있기 때문의 시간 복잡도는 \(O(1)\)입니다. 시프트 연산이 빠졌기 때문에 수행 속도가 훨씬 빠릅니다.
-
빈 상태인지 확인
front의 값이-1이면 데이터가 추가되지 않았음을 의미합니다. 데이터가 없는 상태라 제거할 것도 없습니다. -
꽉 차 있는지 확인
front와rear의 값이 서로 같으면 마지막 요소임을 나타냅니다. 즉 요소가 하나만 있음을 의미합니다. 이럴 때는 큐를 초기의 상태로 돌려 다시 재활용 할 수 있도록 합니다.초기의 상태로 되돌리고 나면 인덱스 증가 연산은 할 필요가 없습니다. 왜냐하면 제거할 데이터가 없으니까요. 그래서
return으로 바로 마무리합니다. -
인덱스 증가
ENQUEUE연산처럼front의 값도 배열의 크기(MAX_SIZE)를 넘어설 수 있기 때문에 모듈러 연산을 통해 인덱스 범위를 적절히 사용하도록 합니다.
FRONT
FRONT 연산은 큐의 앞을 가리키는 위치에 있는 요소의 값을 반환합니다. 기본적으로 DEQUEUE 연산은 값을 제거만 하고 반환하지 않습니다. 물론 구현 방식에 따라 반환하도록 할 수 있습니다.
이 연산은 큐가 비어 있지 않다면 front 위치에 있는 값을 반환합니다. 해당 위치에 접근하여 값을 반환하기 때문에 시간 복잡도는 \(O(1)\)입니다.
큐는 선입선출 방식으로 처리되기 때문에 앞에만 접근할 수 있습니다. 뒤의 데이터를 제거하거나 확인하려면 DEQUEUE 연산으로 일일이 제거 및 확인해야 합니다.
IS EMPTY
IS EMPTY 연산은 큐가 비어 있는 지 확인합니다.
원형 큐에서 빈 상태인지 확인할 때 front의 값이 -1인지 확인합니다. 시간 복잡도는 \(O(1)\)입니다.
IS FULL
IS FULL 연산은 큐가 꽉 차 있는 지 확인합니다.
원형 큐에서 더 이상 데이터를 추가할 수 없음을(꽉 차 있을 때) 확인할 때 rear에 1을 더한 후 모듈러 연산을 수행한 값이 front와 같다면 더 이상 추가할 수 없음을 나타냅니다. 시간 복잡도는 \(O(1)\)입니다.
SIZE
원형 큐의 크기(요소의 수)는 선형 큐와 다르게 순환 구조임을 고려해야 합니다. front와 rear가 모듈러 연산을 통해 이동되기 때문에 이를 이용해야 합니다.
순환 구조로 인해 rear가 front보다 작을 수 있습니다. 즉, rear가 front보다 작은 경우와 front보다 크거나 같은 경우를 생각해야 합니다.
단순 연산 작업만 수행하기 때문에 시간 복잡도는 \(O(1)\)입니다.
rear가 front보다 크거나 같을 때 요소의 수는 rear - front + 1로 구할 수 있습니다. 예를 들어, ENQUEUE 연산을 두 번 수행하면 rear = 1, front = 0입니다. 1 - 0 + 1 = 2로, 요소의 수가 정확히 계산되는 걸 알 수 있습니다.
rear가 front보다 작을 때 요소의 수는 (rear - front + MAX_SIZE) + 1로 구할 수 있습니다. 예를 들어, 작동 원리의 사진을 보면 front = 2, rear = 0인 경우가 있습니다. rear - front = 0 - 2인데 -2는 요소의 수라고 볼 수 없죠. 그리고 배열을 끝을 넘어 순환한 것이기 때문에 MAX_SIZE를 더해 보정을 합니다. 그러면 2가 되겠죠. 여기에 1을 한 번 더해 실제 요소의 수를 구합니다.
모듈러 연산을 수행하는 이유는 rear - front + MAX_SIZE가 MAX_SIZE 이상의 값이 나타날 가능성이 있기 때문에 수행합니다.
-
기본 거리 계산
rear - front연산으로 두 거리를 계산합니다.양수가 나온다면 보정 할 필요가 없지만, 음수가 나오면 양수로 보정할 필요가 있습니다.
-
음수 보정
음수를 양수로 보정하기 위해
MAX_SIZE의 값을 더합니다. -
모듈러 연산
MAX_SIZE로 모듈러 연산을 수행해MAX_SIZE보다 커지는 상황을 방지합니다. -
1
1을 더해 실제 요소의 수로 맞춥니다.rear와front가 같으면0이지만, 요소는 1개 존재합니다. 인덱스 기반으로 추출되기 때문에1을 더해 실제 요소의 수로 변환합니다.
CLEAR
CLEAR 연산은 선형 큐의 CLEAR 연산처럼 간단합니다.
front와 rear의 값을 초깃값으로 되돌리면 되고, 시간 복잡도는 \(O(1)\)입니다.
정리
큐는 기본적으로 선입선출 원칙을 따르는 자료구조입니다.
선형 큐는 배열을 기반으로 한 방향으로 데이터가 관리됩니다. 데이터가 제거되면 앞쪽 빈 공간을 재활용하기 위해 시프트 연산을 수행하는데, 성능 저하의 문제를 갖고 있습니다.
원형 큐는 배열을 기반으로 하되, 논리적으로 배열의 처음과 끝이 연결된 원형 구조를 갖습니다. 이는 요소가 삭제되어도 빈 공간을 재사용할 수 있다는 장점과 선형 큐의 시프트 연산보다 매우 빠르다는 장점을 갖고 있습니다.
| 연산 | 선형 큐의 시간 복잡도 | 원형 큐의 시간 복잡도 |
|---|---|---|
Enqueue |
\(O(1)\) | \(O(1)\) |
Dequeue |
\(O(n)\) | \(O(1)\) |
Front |
\(O(1)\) | \(O(1)\) |
IsEmpty |
\(O(1)\) | \(O(1)\) |
IsFull |
\(O(1)\) | \(O(1)\) |
Size |
\(O(1)\) | \(O(1)\) |
Clear |
\(O(1)\) | \(O(1)\) |
연습문제 1
당신에게 선형 큐가 주어졌습니다. MAX_SIZE는 4이고, front와 rear의 각 초깃값은 0, -1입니다. 이때 아래의 연산을 수행했을 때 최종적으로 front와 rear의 값이 무엇인지 알아내세요.
DEQUEUE 연산은 시프트 연산이 포함되어 있습니다.
코드 작성이 아닌 머리로 풀어보세요.
해답
rear = 3, front = 0
연습문제 2
다음은 C 언어로 구현된 원형 큐의 Dequeue 함수 코드 구현부이며, 문제가 되는 부분이 있습니다.
문제가 되는 부분을 찾고 이유가 무엇인지 설명하세요.
해답
코드에서 문제가 되는 부분은 꽉 차 있는 지 확인을 하지 않는 것과 인덱스 증가식입니다.
-
누락된 로직
front와rear의 값이 같으면 요소가 하나만 있음을 의미합니다. 마지막 요소를 제거한 후 큐가 비었음을 나타내기 위한 로직이 필요합니다. -
인덱스 연산 수식
cqueue->front = cqueue->front + 1;식은 선형 큐에서 사용되는 방식입니다. 원형 큐는 순환 구조를 갖기 때문에 이를 고려해야 합니다.모듈러 연산이 제외됐기 때문에 잘못된 값으로 인해 유효하지 않은 인덱스로 접근할 수 있습니다.
MAX_SIZE로 모듈러 연산을 수행해0으로 되돌아가도록 해야합니다.